

Compute scaling may slow once training durations reach their limits
Since 2020, the training compute used for frontier models has grown by 4.8x per year. About one-third of this scaling can be attributed to longer training runs. But under current conditions, training runs significantly longer than a year appear unlikely.

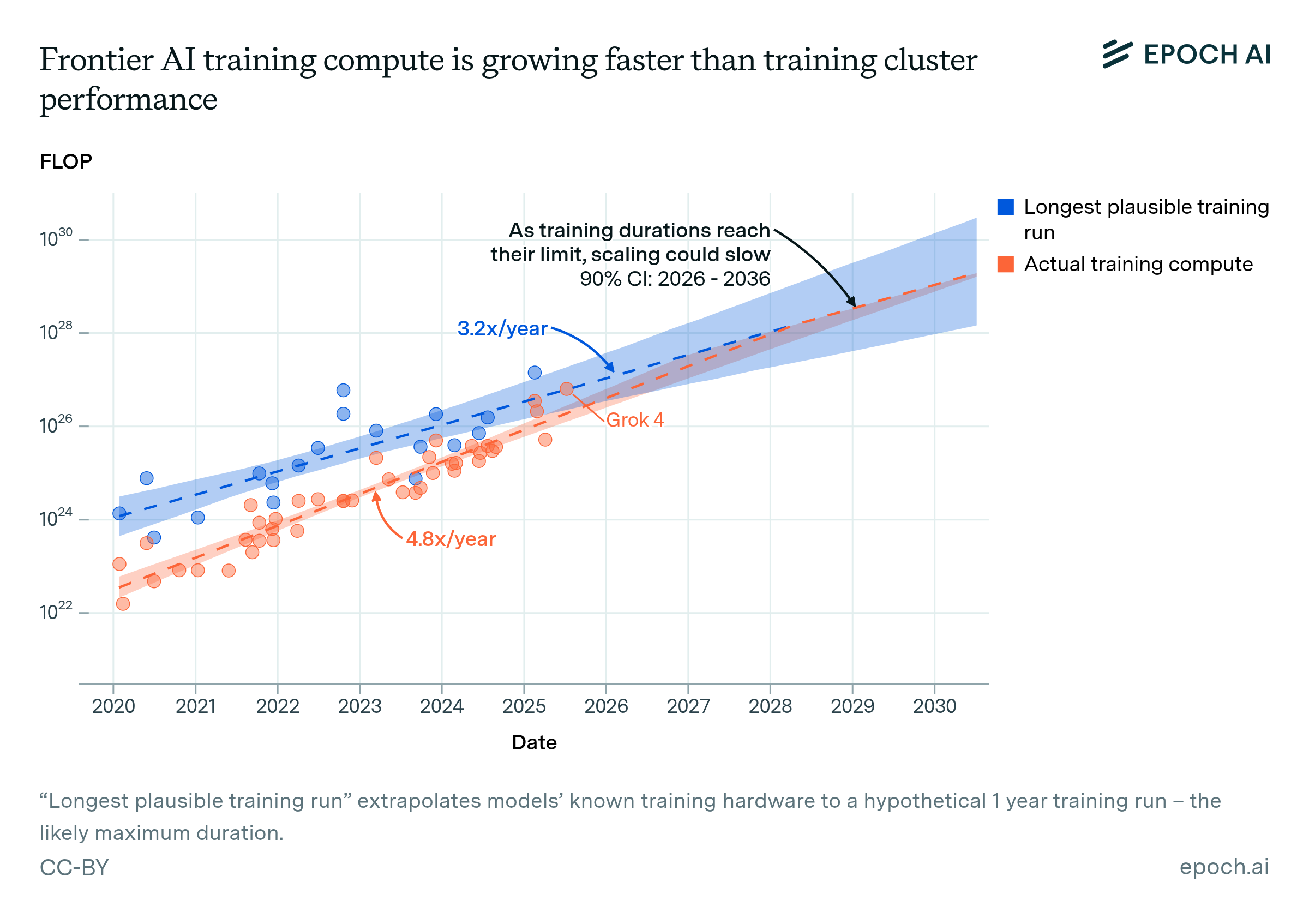
If training time stops increasing, compute growth will slow – unless developers ramp up hardware scaling even faster. They can either speed up the build-out of larger clusters, or spread training across multiple clusters. Indeed, several of today’s largest models (Gemini 2.5 Pro and GPT-4.5) are known to have been trained across multiple clusters.
Learn more
Overview
AI training runs have been getting longer at a rate of about 1.4x each year; on current trends, frontier runs could hit lengths of a full year sometime around 2029 (90% CI: 2026-2036). We compare the compute used to train frontier AI models against the amount of compute their training hardware could have supplied during a hypothetical one-year training run. We believe runs longer than one year are unlikely under current conditions, so we treat this as a limit on training duration for the present analysis.
If training durations stop getting longer, this creates significant headwinds for training compute scaling. Model trainers could respond by trying to increase the pace at which they add new training hardware, either by building larger megaclusters, or by distributing model training across more data centers. But the computing power used for training frontier models is growing at around 2.4x per year, similar to the 2.3x annual growth in global compute stocks from NVIDIA chips. Growth in the computing power used for frontier training runs can only outpace growth in total computing power by using a larger fraction of available compute, and this cannot go on indefinitely.
Data
We obtain estimates of training compute and training duration for frontier AI models from our Notable AI Models dataset. We focus our analysis on frontier LLMs, first filtering to models that include ‘Language’ in their domain, and then identifying models that were among the top 5 by training compute when they were published. We finally filter to those released in 2020 or later, leaving us with a dataset of 42 models.
Analysis
To illustrate the effect of halting training duration growth, we plot two trends: the actual trend in frontier AI model training compute, and the training compute those same models could have used if their training hardware had run for a fixed duration of one year. This latter trend provides a soft upper limit on training compute, barring other changes in training scaling.
To obtain the one-year training duration line, we filter our frontier AI models to a subset of 19 with estimates for both training compute and training duration. We then divide training compute by duration to obtain the aggregate FLOP/s, and multiply this by the number of seconds in a year.
We then estimate a log-linear regression of each metric on publication date. The results of these fits are summarized below:
| Metric | Slope (90% CI) | R2 |
|---|---|---|
| Frontier model training compute | 4.8x per year (4.1 - 5.6) | 0.91 |
| Fixed one-year training run | 3.2x per year (2.3 - 4.3) | 0.63 |
We then project our fitted models forward in time, and calculate the date at which the trends meet. To obtain a confidence interval on this date, we run a bootstrapping exercise, resampling with replacement, fitting new trends, and calculating the crossover date on each iteration. We find a central estimate of March 2029, with a 90% confidence interval ranging from February 2028 to November 2030.
Code for our analysis is available here.
Assumptions and limitations
Our analysis is premised on the assumption that training runs will continue getting longer until they hit 1 year, at which point they will abruptly stop. In reality, training runs may slow well before 1 year durations due to a combination of factors: our most aggressive scenario in “The Longest Training Run” calculates that training runs should not exceed 6 months under the assumed rates of algorithmic progress, hardware progress, and rising investments. Competitive product cycles may further encourage shorter durations.
Conversely, training runs could extend longer than a year, especially if model trainers expect below-trend algorithmic and hardware progress, or slowing investment. If we allow training runs of 3 years, the estimated date at which the trends meet is delayed until 2031 (80% CI: 2028-2039).
Related insights
Explore this data
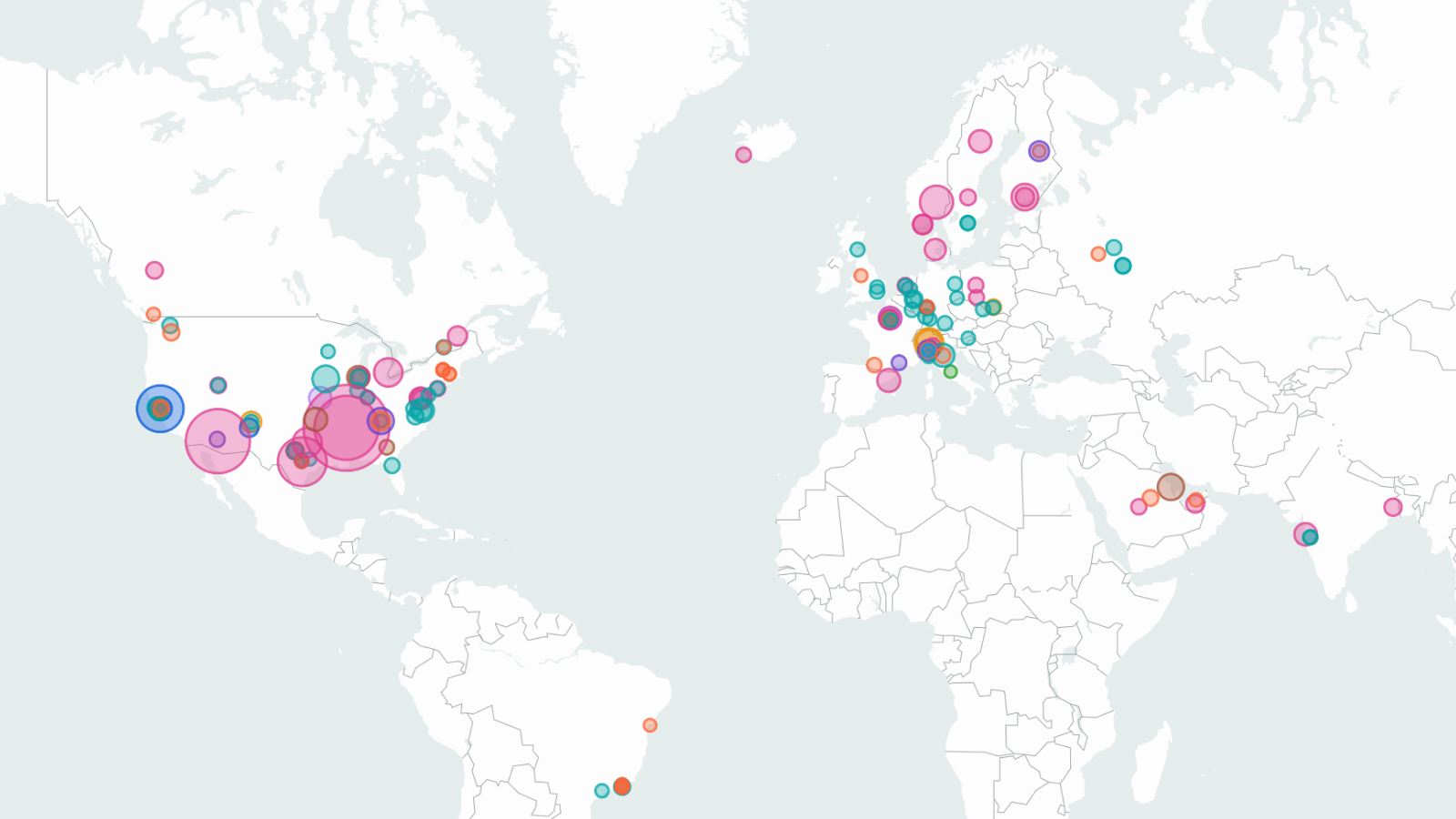
Data on AI supercomputers with map of data centers
Our database of over 500 supercomputers (also known as computing clusters) tracks large hardware facilities for AI training and inference and maps them across the globe.
Updated June 05, 2025
Data on Notable AI Models
Epoch AI's database contains over 900 notable ML models and 400 training compute estimates, offering a detailed exploration of trends in AI development.
Updated June 19, 2024